Partitioning with Python
Sums and Splits
On the subject of hunting for eodermdromes, here are a couple of semi-related partitioning problems.
- for a positive integer, N, find the positive integer sequences which sum to N
- for a sequence, S, find the distinct partitions of that sequence
As an example of the first, the 16 distinct integer sequences which sum to 5 are:
5 4 + 1 3 + 1 + 1 3 + 2 2 + 1 + 2 2 + 1 + 1 + 1 2 + 2 + 1 2 + 3 1 + 1 + 3 1 + 1 + 2 + 1 1 + 1 + 1 + 1 + 1 1 + 1 + 1 + 2 1 + 2 + 2 1 + 2 + 1 + 1 1 + 3 + 1 1 + 4
and of the second, the 8 distinct ways of partitioning the sequence ABCD are:
ABCD A BCD AB CD ABC D A B CD A BC D AB C D A B C D
Note that I’ve counted 2 + 1 + 2, 2 + 2 + 1, and 1 + 2 + 2 as distinct sums totalling 5. That happens to be the formulation of the problem which interested me.
Context
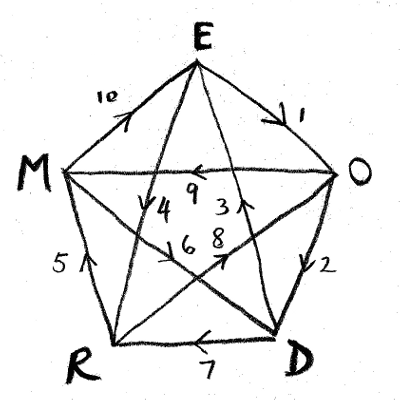
Before discussing a solution to these problems, some context. Recall that an eodermdrome is a sequence which forms an Eulerian circuit through the fully connected graph whose vertices are the set of its elements. Put more simply: when you trace through the letters you get the figure shown, with no edge covered twice. Examples include:
EODERMDROME
ENHANCE ACHE
TAX DEAD TEXT
Eodermdromes turn out to be surprisingly rare. Writing a computer program to find them is a nice exercise in searching and text processing. Clearly, we should start with a collection of words. Then we can generate combinations of words from this collection and filter out the eodermdromes.
(filter eodermdrome? (combinations words))
A large set of words (note: “set” not “collection”, we don’t need duplicates) gives the best chance of success. I started with a file containing more than 35 thousand distinct words. This gives over a billion possible word pairs, and when we consider word triples and quartets the numbers get silly even for a modern computer.
As is so often the case in computing, we have a tension between opposing concerns. We’d like code which separates the task of generating candidates and the task of testing these candidates for eodermdromicity, but in order to run this code in a timely manner we need some of the eodermdrome testing to leak into the candidate generation. For example, we could preprocess the word set removing words which contain double Ls (all, ball, call, ill, Bill, kill …) since these can never appear in an eodermdrome. And we could similarly remove words which end ETE (delete, Pete, effete). As I hope you can see, it’s easy to end up with finickity code and co-dependent functions.
I chose a simple but effective strategy to reduce the search space to something manageable, based on word length. First, then, I loaded my word set into a Python dict collecting lists of words keyed by their length.
>>> from collections import defaultdict
>>> words = defaultdict(list)
>>> for word in open('word-set.txt').read().split():
... words[len(word)].append(word)
Given this dict, picking out single word eodermdromes is easy.
>>> list(filter(is_eodermdrome, words[11])) ['eodermdrome']
How about eodermdromes composed of a 6 letter word followed by a 5 letter word? We can form the cartesian product of the lists of 6 and 5 letter words and filter out the ones we want.
>>> from itertools import product
>>> eod_6_5 = filter(is_eodermdrome, product(words[6], words[5]))
>>> next(eod_6_5)
('earned', 'andre')
>>> next(eod_6_5)
('yearly', 'relay')
How about all eodermdromes of length 11?
>>> from itertools import chain.from_iterable as seq >>> word_lens = sum_to_n(11) >>> candidates = seq(product(*[words[i] for i in s]) for s in word_lens) >>> eods = filter(is_eodermdrome, candidates)
Note here that I’m using Python 3.0, and that filter is therefore a lazy function. The interactive session shown above hasn’t actually started taking anything from these lazily-evaluated streams.
I certainly don’t claim this is the quickest way to search for eodermdromes. In fact, this little program took several hours to complete. But a back-of-an-envelope calculation showed it would complete in a few hours, and that was good enough.
Note also that we haven’t shown an implementation of sum_to_n() yet, which takes us back to the problems posed at the start of this article.
Sum to N
Finding the positive integer series which sum to a positive integer N is a job for itertools.combinations.
from itertools import combinations, chain
def sum_to_n(n):
'Generate the series of +ve integer lists which sum to a +ve integer, n.'
from operator import sub
b, mid, e = [0], list(range(1, n)), [n]
splits = (d for i in range(n) for d in combinations(mid, i))
return (list(map(sub, chain(s, e), chain(b, s))) for s in splits)
The idea here is straightforward: there’s a 1-to-1 correspondence between the sums we want and ordered combinations drawn from the series 1, 2, … n-1. For example, if n is 11 one such combination would be:
(1, 5, 7, 10)
we can extend this by pushing 0 in front and n at the end
(0, 1, 5, 7, 10, 11)
This extended tuple can now be seen as partial sums of a series which sums to 11. Taking differences gives the series
(1-0, 5-1, 7-5, 10-7, 11-10)
which is
(1, 4, 2, 3, 1)
which does indeed sum to 11
1 + 4 + 2 + 3 + 1 = 11
The Python code shown uses a clever idea to implement this staggered differencing, an idea I cleverly stole from one of Raymond Hettinger’s brilliant Python recipes.
{kind=link}
Partitioning a Sequence
from itertools import chain, combinations
def partition(iterable, chain=chain, map=map):
s = iterable if hasattr(iterable, '__getslice__') else tuple(iterable)
n = len(s)
first, middle, last = [0], range(1, n), [n]
getslice = s.__getslice__
return [map(getslice, chain(first, div), chain(div, last))
for i in range(n) for div in combinations(middle, i)]
This recipe shows sum-to-n and partitioning to be very similar problems. In fact, we could easily implement sum_to_n() on top of partition():
def sum_to_n(n):
return ([len(t) for t in p] for p in partition(range(n)))
The posted recipe needs a minor overhaul to get it working with Python 3.0, which does away with __getslice__: getting a slice is simply what __getitem__ does when given a slice object. The 2to3 tool fails to convert the recipe, which must be recast as something like:
from itertools import chain, combinations
def sliceable(xs):
'''Return a sliceable version of the iterable xs.'''
try:
xs[:0]
return xs
except TypeError:
return tuple(xs)
def partition(iterable):
s = sliceable(iterable)
n = len(s)
b, mid, e = [0], list(range(1, n)), [n]
getslice = s.__getitem__
splits = (d for i in range(n) for d in combinations(mid, i))
return [[s[sl] for sl in map(slice, chain(b, d), chain(d, e))]
for d in splits]
Sum to N, again
Here’s a variant implementation of sum_to_n(). The idea here is to fill N slots with a pattern of 0’s and 1’s. We then reduce this pattern to the lengths of runs of repeated elements, giving a series which sums to N. Itertools.product('01', repeat=n) generates all possible binary patterns of length N, which turns out to be twice as many as we want since (e.g.) 00001111100 and 11110000011 represent the same sum, 4 + 5 + 2; hence the n-1 repeat count and the call to chain in the code below1.
from itertools import groupby, chain, product
def ilen(it):
return sum(1 for _ in it)
def sum_to_n(n):
return ([ilen(gp) for _, gp in groupby(chain('1', O1))]
for O1 in product('01', repeat=n-1))
Fun, but the version using combinations is better!
1 My first thought was to use itertools.islice to limit the stream to the first 2n-1 values, but I discovered islice has a surprising limitation.
>>> from itertools import islice, count >>> islice(count(), (1<<31) - 1) <itertools.islice object at 0x63a0c0> >>> islice(count(), (1<<31)) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: Stop argument for islice() must be a non-negative integer or None.
§
so reuse ours