Could OCR conquer the calligraphylion?

Optical character recognition (OCR) algorithms typically process an image in stages:
- convert the image to monochrome
- identify blocks of text
- find lines of text within those blocks
- separate out words, then characters
- extract character outlines
- match outlines to archetypes
- match candidate words to dictionary

These algorithms can be tuned and trained, to particular fonts and dictionaries for example, and the later stages can feedback into earlier ones; but the strategy basically tackles the picture character by character. This form of OCR is a mature and successful technology. It works very effectively with, for example, a page from a Western newspaper; but as with all things language-related, varying cultural conventions can lead to complications. The fundamental assumption that the atoms of a text image are characters may no longer be true. Tesseract, the leading open source OCR engine, comes clean
Tesseract is unlikely to be able to handle connected scripts like Arabic. It will take some specialized algorithms to handle this case, and right now it doesn’t have them.
Mohammad S. M. Khorsheed’s Phd dissertation describes such algorithms, explaining the dimensions of the challenge in more detail:
Arabic scripts are inherently cursive: writing isolated characters in ‘block letters’ is an unacceptable and unused writing style. The letters are context sensitive. Certain character combinations form new ligature shapes which are often font dependent. Some ligatures involve vertical stacking of characters. Since not all characters connect, word boundary location becomes an interesting problem, as spacing may not only separate words but also certain characters within a word.
Here’s an illustration of Arabic characters taking on different forms, depending on position.
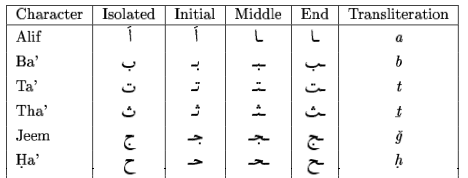
There are some commercially available specialised Arabic OCR packages but I haven’t been able to try them out. They don’t provide information about the algorithms they use.
Could OCR software ever conquer the calligraphylion?

This magical beast demonstrates OCR in reverse: an image which has been converted by hand into text.
This image of a lion originates from Lahore, Pakistan and is part of a rich tradition of zoomorphic calligraphy. This practice, developed in the sixteenth century, employs the flexibility and beauty of Arabic script to delineate living forms such as tigers, parrots, ostriches and cockerels. This is done without disobeying religious injunctions that prohibit their direct depiction.
— Tate Gallery, East West exhibition, 2006-2007
(More zoomorphic calligraphy.)