Power programming
Powerful or dangerous?
Recently I wrote about one of the Google Code Jam challenges, where, perhaps surprisingly, the best answer — the most elegant and obviously correct answer, requiring the fewest lines of code, with virtually zero space overhead, and running the quickest — the very best answer was coded in C++.
Why should this be surprising? C++ is a powerful language.
In my experience there is almost no limit to the damage that a sufficiently ingenious fool can do with C++. But there is also almost no limit to the degree of complexity that a skillful library designer can hide behind a simple, safe, and elegant C++ interface.
— Greg Colvin, “In the Spirit of C”
Yes. And yes! But in this article I wanted to discuss something C++ can’t do. Let’s start with another challenge from the same round of the 2009 Google Code Jam.
Decision trees
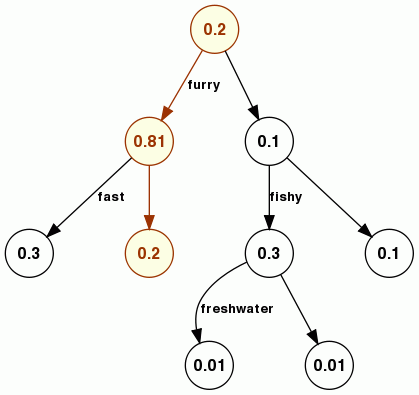
Decision trees — in particular, a type called classification trees — are data structures that are used to classify items into categories using features of those items. For example, each animal is either “cute” or not. For any given animal, we can decide whether it is cute by looking at the animal’s features and using the following decision tree.
(0.2 furry (0.81 fast (0.3) (0.2) ) (0.1 fishy (0.3 freshwater (0.01) (0.01) ) (0.1) ) )

The challenge goes on to describe the structure more formally, then steps through an example calculation. What is the probability, p, that a beaver is cute?
For example, a beaver is an animal that has two features:
furryandfreshwater. We start at the root withpequal to1. We multiplypby0.2, the weight of the root and move into the first sub-tree because the beaver has thefurryfeature. There, we multiplypby0.81, which makespequal to0.162. From there we move further down into the second sub-tree because the beaver does not have the fast feature. Finally, we multiplypby0.2and end up with0.0324— the probability that the beaver is cute.
The challenge itself involves processing input comprising a number of test cases. Each test case consists of a decision tree followed by a number of animals. A solution should parse the input and output the calculated cuteness probabilities.
Cuteness calculator
def cuteness(decision_tree, features):
"""Return the probability an animal is cute.
- decision_tree, the decision tree
- features, the animal's features,
"""
p = 1.0
dt = decision_tree
has_feature = features.__contains__
while dt:
weight, *dt = dt
p *= weight
if dt:
feat, lt, rt = dt
dt = lt if has_feature(feat) else rt
return p
Calculating an animal’s cuteness given a decision tree and the animal’s features isn’t hard. In Python we don’t need to code up a specialised decision tree class — a nested tuple does just fine. The cuteness() function shown above descends the decision tree, switching left or right according to each feature’s presence or absence. The efficiency of this algorithm is proportional to the depth of the tree multiplied by the length of the feature list; as far as the code jam challenge goes, it’s not a concern.
>>> decision_tree = (
... 0.2, 'furry',
... (0.81, 'fast',
... (0.3,),
... (0.2,),
... ),
... (0.1, 'fishy',
... (0.3, 'freshwater',
... (0.01,),
... (0.01,),
... ),
... (0.1,),
... ),
... )
>>> beaver = ('furry', 'freshwater')
>>> cuteness(decision_tree, beaver)
0.032400000000000005
No, the real problem here is how to parse the input data to create the decision trees and feature sets. As you can see, though, the textual specification of a decision tree closely resembles a Python representation of that decision tree. Just add punctuation.
| Specification | Python |
(0.2 furry
(0.81 fast
(0.3)
(0.2)
)
(0.1 fishy
(0.3 freshwater
(0.01)
(0.01)
)
(0.1)
)
) | (0.2, 'furry',
(0.81, 'fast',
(0.3,),
(0.2,),
),
(0.1, 'fishy',
(0.3, 'freshwater',
(0.01,),
(0.01,),
),
(0.1,),
),
) |
Rather than parse the decision tree definition by hand, why not tweak it so that it is a valid Python nested tuple? Then we can just let the Python interpreter eval the tuple and use it directly.
Eval
A program’s ability to read and execute source code at run-time is one of the things which makes dynamic languages dynamic. You can’t do it in C and C++ — no, sneaking instructions past the end of a buffer doesn’t count. Should you do it in Python? Well, it won’t hurt to give it a try.
spec = '''\
(0.2 furry
(0.81 fast
(0.3)
(0.2)
)
(0.1 fishy
(0.3 freshwater
(0.01)
(0.01)
)
(0.1)
)
)
'''
tuple_rep = re.sub(r'([\.\d]+|\))', r'\1,', spec)
tuple_rep = re.sub(r'([a-z]+)', r'"\1",', tuple_rep)
decision_tree = eval(tuple_rep)[0]
Here, we start with the input specification of the decision tree (imagine this has been read directly from standard input). The first regex substitution inserts commas after numbers, and right parentheses. The second substitution quotes and inserts a comma after feature strings. This turns the decision tree’s specification into a textual representation of a nested Python tuple. We then eval that tuple and assign the result to decision_tree — a Python decision tree we can go on and use in the rest of our program. And that’s the code jam challenge cracked, pretty much.
>>> from pprint import pprint >>> pprint(decision_tree) (0.2, 'furry', (0.81, 'fast', (0.3,), (0.2,)), (0.1, 'fishy', (0.3, 'freshwater', (0.01,), (0.01,)), (0.1,)))
(Minor wrinkle: you’ll have spotted the final decision tree is the first element of the evaluated tuple. That’s because the regex substitution puts a trailing comma after the right parenthesis which closes the decision tree specification, which turns tuple_rep into a one-tuple. The single element contained in this one-tuple is what we need.)
Dynamic or hacky?
As you can see, it doesn’t take much code to pull the decision tree in ready for use. Python allows us to convert between text and code and to execute code within the current environment: you just need to keep a clear head and remember where you are. Regular expressions may not have the first class language support they enjoy in Perl and Ruby, but they are well supported, and the raw string syntax makes them more readable.
Certainly, this code snippet is easier to put together than a full blown parser, but I think it will take more than this to convince a C++ programmer that Python is a powerful language, rather than a dangerous tool for ingenious fools. It fails to convince me. I can’t remember ever using eval or exec in production code, where keeping a separation between layers is more important than speed of coding.
Jam to golf
![]()
That said, Python is a fine language for scripting, and speed of coding is what matters in this particular challenge. Just for fun, what if there were a prize for brevity? Then of course Perl would win!
say("Case #$_:"),
$_=eval"''".'.<>'x<>,
s:[a-z]+:*(/ $&\\s/?:g,s/\)\s*\(/):/g,
eval"\$_=<>;say$_;"x<>for 1..<>
Note that this does more than simply parse a decision tree — it’s a complete solution to the code jam challenge, reading trees, features, calculating cutenesses, and producing output in the required format. Sadly that’s all I can say about it because the details of its operation are beyond me.
Code vs data
Using Python to dynamically execute code may not generally be needed or welcomed in Python production code, and over-reliance on the same trick risks reinforcing Perl’s “write only” reputation, but Python and Perl aren’t the only contenders. The equivalence of code and data marks Lisp’s apotheosis. Take a look at a Lisp solution to the challenge. This one is coded up in Arc.
(def r () (read))
(for i 1 (r)
(prn "Case #" i ":")
(r)
(= z (r))
(repeat (r)
(r)
(loop (= g (n-of (r) (r))
c z
p 1)
c
(= p (* (pop c) p)
c (if (pos (pop c) g)
(c 0)
(cadr c))))
(prn p)))
Which challenge does this solve?
I meant the code golf challenge, of solving the decision tree problem using the fewest keystrokes. At 154 characters this Arc program is nearly half as long again as the winning Perl entry, but it’s hardly flabby. What really impresses me, though, is that the code is (almost) as readable as it is succinct. It’s elegant code. The only real scars left by the battle for brevity are the one character variable names. Here’s the same code with improved variable names and some comments added. It’s the (read) calls which evaluate expressions on standard input. The (for ...) and (repeat ...) expressions operate as you might expect. The third looping construct, (loop ...) initialises, tests and proceeds, much like a C for loop.
(for i 1 (read) ; Read N, # test cases, and loop
(prn "Case #" i ":")
(read) ; Skip L, # lines taken by decision tree
(= dtree (read)) ; and read the tree in directly
(repeat (read) ; Repeat over A, # animals
(read) ; Skip animal name
; Read in the animal's features and walk down the
; decision tree calculating p, the cuteness probability
(loop (= features (n-of (read) (read))
dt dtree
p 1)
dt
(= p (* (pop dt) p)
dt (if (pos (pop dt) features)
(car dt)
(cadr dt))))
(prn p)))
You could argue the elegance of this solution is due to the fact the input comprises a sequence of tokens and S-expressions. If commas had been used to separate input elements and the text fields had been enclosed in quotes, then maybe a Python solution would have been equally clean. Or if the input had been in XML, then we’d be looking to a library rather than eval for parsing the input.
It’s a fair point, but the equivalence of code and data counts as Lisp’s biggest idea. Where Python’s eval is workable but rarely needed, Lisp’s (read) is fundamental.
Powerful language vs power user?
So, the most elegant answer to the code jam decision tree challenge would also be the quickest to write, and it would be written in Lisp. Did code jam champion, ACRush, submit a Lisp solution?
Absolutely not!
Another fundamental thing about Lisp is that it’s straightforward to parse. A C++ expert can knock up an input parser for decision trees and features to order. ACRush brushed this round aside with a perfect score, taking just 45 minutes to code up working C++ solutions to this question and two others. I’ve reproduced his solution to the decision tree challenge at the end of this article. It’s plain and direct. Given the time constraints, I think it exhibits astonishing fluency — the work of someone who can think in C++.
In this article we’ve encountered four programming languages:
- Python
- Perl
- Lisp
- C++
These languages are very different but they share features too. They are all mature, popular and well-supported1. Each is a powerful general purpose programming language. But ultimately, the power of the programmer is what matters.
Appendix A: First impressions of Arc
Here’s another revision of the Arc solution, this time decomposed into subfunctions. I found no complete formal documentation of Arc. You’ll have to read the source and follow the forum, and to actually run any code you’ll have to download a an old version of MzScheme. The official line is: by all means have a play, but expect things to change. That said, the language looks delightful, practical, and quite onion free. The tutorial made me smile. Recommended reading.
; The input is a sequence of valid Arc expressions.
; Create some read aliases to execute these.
(= skip read
decision-tree read
n-features read
n-tests read
n-animals read)
(def animal-features ()
; Get an animal's features
(skip) ; animal name
(n-of (n-features) (read)))
(def cuteness (dtree features)
; Calculate cuteness from a decision tree and feature set
(= dt dtree
p 1.0)
(while dt
(= p (* (pop dt) p)
dt (if (pos (pop dt) features)
(car dt)
(cadr dt))))
p)
; Loop through the tests, printing results
(for i 1 (n-tests)
(prn "Case #" i ":")
(skip) ; # lines the tree specification takes
(= dtree (decision-tree))
(repeat
(n-animals)
(prn (cuteness dtree (animal-features)))))
Appendix B: C++ solution
Here’s champion ACRush’s C++ solution. I’ve removed some general purpose macros from the top of the file. You can download the original here.
#include <set>
#include <string>
#include <vector>
#include <sstream>
#include <cstdio>
#include <cstdlib>
using namespace std;
vector<string> A;
vector<int> P;
set<string> M;
#define SIZE(X) ((int)(X.size()))
double solve(int H,int T)
{
H++;T--;
double p=atof(A[H].c_str());
if (H==T) return p;
if (M.find(A[H+1])!=M.end())
return p*solve(H+2,P[H+2]);
else
return p*solve(P[T],T);
}
int main()
{
freopen("A-large.in","r",stdin);freopen("A-large.out","w",stdout);
int testcase;
scanf("%d",&testcase);
for (int caseId=1;caseId<=testcase;caseId++)
{
int nline;
scanf("%d",&nline);
A.clear();
char str[1024];
gets(str);
for (int i=0;i<nline;i++)
{
gets(str);
string s="";
for (int k=0;str[k];k++)
if (str[k]=='(' || str[k]==')')
s+=" "+string(1,str[k])+" ";
else
s+=str[k];
istringstream sin(s);
for (;sin>>s;A.push_back(s));
}
P.resize(SIZE(A),-1);
vector<int> stack;
for (int i=0;i<SIZE(A);i++)
if (A[i]=="(")
stack.push_back(i);
else if (A[i]==")")
{
int p=stack[SIZE(stack)-1];
P[i]=p;
P[p]=i;
stack.pop_back();
}
int cnt;
printf("Case #%d:\n",caseId);
for (scanf("%d",&cnt);cnt>0;cnt--)
{
scanf("%s",str);
M.clear();
int length;
for (scanf("%d",&length);length>0;length--)
{
scanf("%s",str);
M.insert(str);
}
double r=solve(0,SIZE(A)-1);
printf("%.12lf\n",r);
}
}
return 0;
}
Appendix C: A Python Solution
import re
from itertools import islice
def cuteness(decision_tree, features):
p = decision_tree[0]
if len(decision_tree) > 1:
_, feat, lt, rt = decision_tree
p *= cuteness(lt if feat in features else rt, features)
return p
def read_decision_tree(spec):
tuple_rep = re.sub(r'([\.\d]+|\))', r'\1,', spec)
tuple_rep = re.sub(r'([a-z]+)', r'"\1",', tuple_rep)
return eval(tuple_rep)[0]
def take_lines(lines, n):
return ''.join(islice(lines, n))
def main(fp):
lines = iter(fp)
n_tests = int(next(lines))
for tc in range(1, n_tests + 1):
print("Case #%d:" % tc)
tree_spec = take_lines(lines, int(next(lines)))
dtree = read_decision_tree(tree_spec)
n_animals = int(next(lines))
for line in islice(lines, n_animals):
features = set(line.split()[2:])
print(cuteness(dtree, features))
import sys
main(sys.stdin)
Notes
1 (Arc may not be mature, popular or well-supported; but Lisp certainly is.)